
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- java
- 글또
- Python
- 코드스테이츠
- Zerobase
- 자료구조
- 자바
- node.js
- codestates
- context switching
- 컴퓨터공학
- 테스트코드
- 비동기
- python algorithm
- 개발공부
- 운영체제
- JavaScript
- REACT
- 알고리즘
- Computer Science
- algorithm
- 프로그래머스
- OS
- useState
- 파이썬 알고리즘 인터뷰
- 파이썬
- Operating System
- 자바스크립트
- react 기초
- execution context
- Today
- Total
Back to the Basics
[Database][ElasticSearch] Score는 어떻게 계산이 될까? 본문

서론 .. 주저리주저리
이번에 진행하는 프로젝트에서 full text search를 하기위해 Elastic Search를 적용하게 되었다.
(여담이지만 개발공부를 할 때에는 MySQL, 회사에 들어와서는 PostgreSQL등 관계형 DB들만 사용해봤는데 No SQL을 직접 사용해 볼 기회가 와서 좋다)
full text search를 해야하는 이유는 바로 통합검색을 하기 위함이었다.
기존에 사용하던 방식은 postgreSQL 에서 통합검색을 하는 방식이었는데 자유분방한 사용자 입력에 대해 부분검색을 구현하는데 한계가 있어 결국 elasticSearch를 사용하기로 하였다.
참고로 full text search란 DB 내에서 특정 키워드나 문서와 일치하는 텍스트를 찾는 검색 방법이다. 일반 검색과 다른점은 일반 검색의 경우 특정 컬럼을 대상으로 하는 반면 full text search는 문서나 database내의 모든 텍스트를 검색 대상으로 한다.
elasticSearch에 데이터까지 적재를 해놓고 검색 test를 하라는 task가 주어졌다. 나는 ElasticSearch(명칭이 길기 때문에 ES라고 퉁치겠다)는 처음이기 때문에 책까지 구매해서 공부하면서 이 task를 하게되었다. (재밌..)
일단 단순히 match로 쿼리를 해보았다. 그런데 웬걸.. 정확도가..정확도가 정확도가..말도안되게 안나오더라..😱 이유는 토크나이저를 제대로 설정하지 않아서이기도한데, 이 이야기는 주제와는 멀어지니 다음에 정리를 해보도록 하겠다. (노션에 정리는 해놨지만 정리가 안된 정리(?) 라서 아직 블로깅 하기에는 좀 그렇다) 와일드카드 등의 다양한 쿼리도 시도해보았지만 원하는 결과를 제일 첫 번째로 나오지 않더라.. #@5!#$%
어떤 결과는 원하는 결과가 A라면 전혀 원하는 결과가 아닌 B가 첫 번째 결과로 나오고 A는 두 번째 또는 저~밑에 결과로 나오는 경우가 있었다.
예를 들면 아래와 같이 "강남구 병원" 을 검색하면 적어도 강남구의 "병원" 은 나와줘야하는데.. 이게 안나온다.. (심한욕) 🤬🤬🤬
{
"query": {
"match": {
"_search": "강남구 병원"
}
}
}
<result>
{
"_score": 15.527043,
"_source": {
"jibunAddr": "서울특별시 강남구 대치동 898-33",
"_search": "대치동 898-33 선릉로76길 5-9 강남구 대치동 다세대주택 ",
"roadAddr": "서울특별시 강남구 선릉로76길 5-9"
}
},
{
"_score": 13.551037,
"_source": {
"jibunAddr": "서울특별시 강남구 삼성동 8",
"_search": "삼성동 8 선릉로 668 강남구 보건소 별관 ",
"roadAddr": "서울특별시 강남구 선릉로 668"
}
},
{
"_score": 13.551037,
"_source": {
"jibunAddr": "서울특별시 강남구 역삼동 682-27",
"_search": "역삼동 682-27 선릉로 573 강남구 선거관리위원회 ",
"roadAddr": "서울특별시 강남구 선릉로 573"
}
},
{
"_score": 12.762758,
"_source": {
"jibunAddr": "서울특별시 강남구 개포동 14-2",
"_search": "개포동 14-2 개포로 617-8 강남구 건강가정지원센터 ",
"roadAddr": "서울특별시 강남구 개포로 617-8"
}
}위의 결과를 잘 보면 _score라는 것이 있다. ES는 내부적으로 저 _score 순으로 document에 점수를 계산하고 _score순으로 정렬해서 보여준다. 그러니끼 내가 원하는 결과들은 _score가 겁나 낮다는 것이다.
저 score는 도대체 어떤 기준으로 계산이 되는지 알아야 어떻게 쿼리를 개선할지 감이라도 잡을 수 있을 것 같다.
서론이 매우 길었지만 .. 이런 이유로 ES에서 score를 어떻게 계산하는지 알아보았다.
ElasticSearch의 score계산 방법
ES에는 다양한 점수 계산 알고리즘(유사성 모델)을 사용한다.
참고 - 공식문서
자세한 것은 공식문서를 확인해보자. 간단하게 정리하면 아래와 같다 (GPT한테 요약해달라고 했다)
1. BM25 (Okapi BM25): 가장 일반적으로 사용되는 알고리즘입니다. 문서의 관련성을 평가하는 데 여러 요소를 고려합니다. (예: 문서 길이, 단어 빈도, IDF (역 문서 빈도))
장점: 높은 정확성, 다양한 상황에 적용 가능
단점: 복잡한 계산, 일부 경우 다른 알고리즘보다 느릴 수 있음
사용 시나리오: 일반적인 검색, 뉴스 검색, e커머스 검색 등
2. TF-IDF (Term Frequency-Inverse Document Frequency): 문서 내 단어의 중요도를 평가하는 알고리즘입니다. (단어 빈도 * IDF)
장점: 간단하고 빠른 계산, 특정 단어에 대한 문서의 관련성 평가에 효과적
단점: BM25보다 정확도가 떨어질 수 있음, 단어 순서 고려하지 않음
사용 시나리오: 기본적인 검색, 특정 단어 기반 검색 등
3. Match Query: 문서 내 특정 문구나 단어가 포함되어 있는지 여부를 기반으로 Score를 계산합니다.
장점: 간단하고 빠른 계산, 정확한 일치 여부 판단에 효과적
단점: BM25, TF-IDF와 같은 관련성 평가 기능 부족
사용 시나리오: 정확한 일치 여부 판단, 필터링 등
4. PLM (Product of Language Models): Transformer 기반 신경망 모델을 사용하여 문서의 의미적 유사성을 평가합니다.
장점: 높은 정확성, 문맥 고려, 의미적 유사성 평가에 효과적
단점: BM25보다 느린 계산, 많은 학습 데이터 필요
사용 시나리오: 질의 응답, 추천 시스템, 의미적 검색 등
5. LSI (Latent Semantic Indexing): 문서 간의 잠재적인 의미적 관계를 파악하여 Score를 계산합니다.
장점: 단어의 의미적 관계를 고려하여 관련성 평가, 동의어 검색에 효과적
단점: 느린 계산, 많은 학습 데이터 필요
사용 시나리오: 동의어 검색, 문서 군집화, 의미적 분석 등
6. Geo Distance: 검색 결과와 사용자 위치의 거리를 기반으로 Score를 계산합니다.
장점: 위치 기반 검색에 효과적, 사용자에게 가장 가까운 결과 우선 표시
단점: 위치 정보가 없는 문서는 평가 불가능
사용 시나리오: 위치 기반 검색, 지도 검색, 음식점 검색 등위에서보면 신경망 모델을 사용하는 방법들도 있는데 이런 알고리즘들은 어느정도의 학습 데이터가 필요해보인다.
주소검색의 경우 시도 / 시군구 / 읍면동 등 보통 검색을 하는 순서가 정해져있다. TF-IDF 의 경우 순서를 보장하지는 않는다고한다.
일단 기본적으로 사용하는 알고리즘은 BM25이다. 지금 사용하고있고 가장 기본적으로 사용되는 BM25 에 대해서 알아보자
BM25 알고리즘
BM25알고리즘은 공식문서에도 나와있듯이 TF/IDF based similarity 이다.
TF는 단순하게 말하면 "해당 필드 에서 해당 단어가 얼마나 자주 나타나는지"를 의미하고 IDF(inverse document frequency)는 "역 문서 빈도" 이다.
TF는 대충 알겠는데 IDF는 뭔가 어렵다. 조금 더 추가보충하자면.. DF는 특정 단어 t가 등장한 문서의 수 (단순히 등장했던 문서의 수만을 의미한다)를 의미하고 IDF는 1/DF -> "역 문서 빈도 DF에 반비례하는 수" 이다. 이는 어디서나 많이 나올 수 있는 단어들("은", "는", "이", "가" 와 같이)에 의해 무분별하게 score가 높아지는 것을 막기 위해 역수를 취함으로써 단어의 중요도를 낮춰주는 수이다.
아래의 계산 공식을 보면 결국 TFnorm 과 IDF의 합을 곱해줌으로써 score를 얻는 것을 알 수 있다. (TF-IDF 알고리즘도 비슷한 방법이지만 BM25의 경우 각 파라미터에 보정값을 추가함으로써 조금 더 개선시킨 것이라고 한다)
계산 공식은 아래와 같다

위의 그림은 아래의 블로그에서 퍼왔다. 참고로 수식에대해서도 잘 설명을 해주고있으니 궁금하면 확인해보자.
그리고 잘 ~ 보면 TFnorm을 계산할 때 아래와 같이 해당 document의 길이를 모든 document의 평균길이로 나눈다. 그리고 그것이 분모로 들어가있다.
즉, document의 길이가 길수록 TFnorm의 분모는 커지고 TFnorm의 값은 작아진다. 이를 통해 document의 길이가 짧을수록 점수를 더 많이 받는다는 것을 알 수 있다. 참고로 아래의 수식에서 f(qi, D) 는 tf를 의미한다.
참고로 k1 와 b는 우리가 조정할 수 있는 변수 값이며 b는 문서의 길이에 얼마나 영향을 줄지를 설정할 수 있고 k1 은 반복적으로 나오는 토큰에 대한 패널티 여부를 조정할 수 있다고 한다. 뭔가 더 세밀하게 조정하려면 이 값을 서비스에 맞도록..설정해야하나..?)
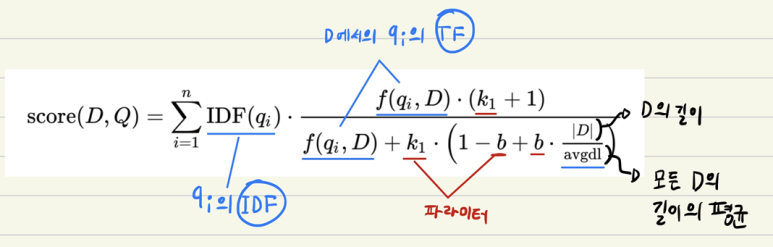
위에서 말했지만 단순하게 결론을 내려보면 BM25가 적용되어있는 ES에서 score는 단어가 나오는 빈도수 X IDF 라고 할 수 있다.
(여기에서 갑자기 궁금한 것이 주소에서 IDF는 무엇이 될까 ? 모든 문서에서 자주 나오는 시,도,군,구,읍,면,동 과 같은 행정명칭의 끝에 오는 단어가 될까?)
그렇다면 이게 실제 어떻게 계산이 되는지 직접 쿼리를 통해 알아보도록 하자
_explain 을 통해 실제 score 계산을 확인해보자
테스트를 할 주소는 아래와 같다
- 참고로 토크나이징은 ngram을 사용했다 (토크나이저 관련해서도 다음 포스팅으로 올려보도록 하겠다)
"test_filter_ngram_2_4":
{
"type": "ngram",
"min_gram": "2",
"max_gram": "4"
}
- 목표 주소 : 목표 주소 : 퇴촌면 우산리 산 279-4
- 검색어 : 우산리 279-4
- 쿼리 : _search 필드로 검색을 하였고 match 사용 하였다
{
"query" : {
"match" : { "_search" : "우산리 279-4" }
}
}
- 1번 결과 : 원하는 결과
{
"_score": 10.631649,
"_source": {
"finalBuildingName": "서울특별시학생교육원퇴촌야영교육장",
"jibunAddr": "경기도 광주시 퇴촌면 우산리 산 279-4",
"_search": "퇴촌면 우산리 산 279-4 천진암로 1152-51 서울특별시학생교육원퇴촌야영교육장 ",
"roadAddr": "경기도 광주시 천진암로 1152-51"
}
}- 2번 결과 : 첫 번째 결과로 나온 결과
{
"_score": 10.846484,
"_source": {
"finalBuildingName": "",
"jibunAddr": "충청북도 청주시 청원구 내수읍 우산리 479-4",
"_search": "내수읍 우산리 479-4 우산1길 17-4 ",
"roadAddr": "충청북도 청주시 청원구 우산1길 17-4"
}
내가 원하는 결과는 "퇴촌면 우산리 산 279-4" 인데 나온 결과는 "내수읍 우산리 479-4" 이라는 엉뚱한 결과이다.
_score를 비교해보면 원하는 결과는 10.631649 , 첫 번째로 나온 결과는 10.846484 로 0.2148 차이가 난다..😮💨 😇 😂
일단 쿼리 결과만 갖고 확인을 해보자.
위에서 확인했던 TF x IDF에 따라 점수가 결정된다고 했는데, _search 필드를 보면 첫 번째 결과는 우산리가 한 번 나오고 _search의 길이도 엄청 길다. 반면 두 번째 결과를 확인해보면 상대적으로 길이가 짧고 "우산" 이라는 단어가 두 번은 나온다.
IDF가 어떻게 계산되는지는 예측이 안되니까 일단 pass..
이렇게만 봐도 TF는 document 길이가 길수록 낮기도하고 "우산" 이라는 단어의 빈도수도 2번 결과가 더 높을 것 같기도하다.
그런 진짜로 어떻게 계산이 되는지 확인해보자. 참고로 조금 복잡하다
확인해보는 방법은 아래와 같이 _explain/해당_document_id 를 해주면 된다.
GET index_name/_explain/해당_document_id
{
"query" : {
"match" : { "_search" : "우산리 279-4" }
}
}- 첫 번째 나온 결과
- _explain 쿼리 결과 (엄청 길다) 분석은 그 아래에 이어서..
# 우산리에 대한 score 계산
"value": 6.3825197,
"description": "weight(Synonym(_search:산리 _search:우산 _search:우산리) in 298356) [PerFieldSimilarity], result of:",
# 산리, 우산,우산리 동의어로 처리
# 검색 엔진은 "우산리"뿐만 아니라 "산리", "우산"을 포함하는 문서들도 검색 결과에 포함
"details": [
{
"value": 6.3825197,
"description": "score(freq=4.0), computed as boost * idf * tf from:",
# score(freq=4.0): 문서 내에서 검색된 용어(위의 경우에는 시노님으로 취급되는 용어들)가 출현한 빈도수 (4) 에 기반한 점수.
"details": [
{
"value": 2.2,
"description": "boost",
"details": []
},
{
"value": 3.2274177,
"description": "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details": [
{
"value": 281020,
"description": "n, number of documents containing term",
"details": []
},
{
"value": 7085780,
"description": "N, total number of documents with field",
"details": []
}
]
},
{
"value": 0.89890605,
"description": "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details": [
{
"value": 4,
"description": "termFreq=4.0",
"details": []
},
{
"value": 1.2,
"description": "k1, term saturation parameter",
"details": []
},
{
"value": 0.75,
"description": "b, length normalization parameter",
"details": []
},
{
"value": 5,
"description": "dl, length of field",
"details": []
},
{
"value": 30.029375,
"description": "avgdl, average length of field",
"details": []
}
]
}
]
}
]
},
------------------------------------
# 279-4에 대한 score 계산
{
"value": 4.4639645,
"description": "weight(Synonym(_search:-4 _search:27 _search:279 _search:279- _search:79 _search:79- _search:79-4 _search:9- _search:9-4) in 298356) [PerFieldSimilarity], result of:",
"details": [
{
"value": 4.4639645,
"description": "score(freq=7.0), computed as boost * idf * tf from:",
"details": [
{
"value": 2.2,
"description": "boost",
"details": []
},
{
"value": 2.1594727,
"description": "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details": [
{
"value": 817599,
"description": "n, number of documents containing term",
"details": []
},
{
"value": 7085780,
"description": "N, total number of documents with field",
"details": []
}
]
},
{
"value": 0.93961585,
"description": "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details": [
{
"value": 7,
"description": "termFreq=7.0",
"details": []
},
{
"value": 1.2,
"description": "k1, term saturation parameter",
"details": []
},
{
"value": 0.75,
"description": "b, length normalization parameter",
"details": []
},
{
"value": 5,
"description": "dl, length of field",
"details": []
},
{
"value": 30.029375,
"description": "avgdl, average length of field",
"details": []
}
]
}
]
}
]
}
너무 길다.. 간략하게 분석을 하면 아래와 같다
- 우산리 score (6.3825197)
- idf (3.2274177)
- 281020
- 7085780
- tf (0.89890605)
- termFreq : 4 (해당 문서에서 단어( 시노님으로 취급되는 용어들) - 높을수록 해당 단어는 문서에서 중요한 역할을 하는 것으로 간주)
- dl : 5 (field의 길이, 일반적으로 문서 길이가 길수록
tf값이 감소하여, 짧은 문서에서 동일한 단어가 더 중요하게 평가됨) - avgdl : 30.029375
- idf (3.2274177)
- 279-4 score (4.4639645)
- idf (2.1594727)
- 817599
- 7085780
- tf (0.93961585)
- termFreq =7
- dl : 5
- avgdl : 30.029375
- idf (2.1594727)
- 목표 결과 - 이건 실제 _explain 결과는 생략하겠다. (너무 길다)
- 우산리 (6.121274)
- idf (3.2274177)
- 281020
- 7085780
- tf (0.8621126)
- termFreq=3
- dl : 6
- avgdl : 30.029375
- idf (3.2274177)
- 279-4 (4.510375)
- idf (2.1594727)
- 817599
- 7085780
- tf (0.9493847,)
- termFreq=9
- dl : 6
- avgdl : 30.029375
- idf (2.1594727)
위의 점수를 비교해봄면 "우산리" 에 대한 점수는 첫 번째로 나온 결과가 +0.26 높고 279-4는 -0.046 낮은 것을 알 수 있다. 합쳐보면 위에서 봤던 0.2148 차이이다
그리고 이것은 토큰화방법과 관련이 있긴한데 각 토큰화된 terms 들 중 우산리 로 취급되는(동의어로 취급되는) 용어가 1번 결과에 더 많다.
weight(Synonym(_search:산리 _search:우산 _search:우산리) in 298356)
즉, 위에서 알고리즘 수식에서 봤던 것처럼 빈도수가 더 높고, 길이가 짧아서 점수가 더 놓게 나왔던 것이다.
이렇게 스코어가 어떻게 계산이 되는지 알아보았다. 복잡복잡 ~
여기서 나는 _search 라는 필드에 모든 정보를 다 넣어서 검색을 한 번에 때렸다. 일단 이게 문제가 될 수 밖에 없는 것은 줄필요한 정보들이 들어있기 때문이다. 불필요하게 긴 건물명이 들어있어서 _search 필드의 길이가 길어졌고 우산리 우산길 처럼 불필요한 정보로 인해 빈도수가 높아진 것도 문제가 되었다.
이제 문제가 무엇있지 알게되었지만 또다른 문제가 생긴다. 이건 해결이 되면 다음 포스팅에서 또 올려보도록 하겠다..
지금은 새벽이라 이제 그만 써야지.. 내일 출근해야하니까..
'Backend Development > DATABASE' 카테고리의 다른 글
| [Index] Composite Index (복합 인덱스) (0) | 2024.11.24 |
|---|---|
| [Database][Postgresql] Full Text Search(FTS) -1 (0) | 2024.10.10 |
| [Database][PostgreSQL]Database Page - Postgres를 기준으로 (1) | 2024.04.08 |
| [Database] SQL 기본 - DDL (0) | 2022.01.06 |



