
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- 테스트코드
- 컴퓨터공학
- 운영체제
- useState
- node.js
- codestates
- Python
- java
- Operating System
- 코드스테이츠
- execution context
- 개발공부
- 글또
- OS
- python algorithm
- 파이썬 알고리즘 인터뷰
- REACT
- 파이썬
- 자바스크립트
- 프로그래머스
- 자료구조
- context switching
- 자바
- JavaScript
- react 기초
- algorithm
- Zerobase
- Computer Science
- 알고리즘
- 비동기
- Today
- Total
Back to the Basics
[Computer Science] MapReduce Model 이란? 본문
본론으로 들어가기 전에
MapReduce Model을 구글링 해보니 먼저 Apache hadoop과 관련이 있으므로 이 Hadoop이라는 놈부터 간단하게 알아보자.
Hadoop 공식 홈페이지에서 소개하는 글은 이러하다. "The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. "이라고 한다. 즉, Apache Hadoop 은 대량의 데이터의 병렬 처리를 위한 framework이다. 주로 빅데이터 분석을 위해 사용한다고 한다.
쉽게 말하면, 대용량의 데이터는 적은 비용으로 더 빠르게 분석할 수 있는 소프트웨어이며, 빅데이터 처리와 분석을 위한 플랫폼 중 표준으로 자리 잡고 있다고 한다. 여러 대의 컴퓨터로 데이터를 분석하고 저장하는 방식은 비용과 시간이 많이 들며, hadoop으로 이해 이를 다축 시킬 수 있었다고 한다.
Hadoop은 저장소를 담당하는 HDFS(Daoop Distributed File System)과 대용량의 데이터 처리를 위한 분산 프로그래밍 모델(software framework)인 MapReduce로 구성된다.
MapReduce 이란?
정렬된 데이터를 분산처리 (Map)하고 이를 다시 합치는 (Reduce) 과정을 수행한다. MapReduce framework를 이용하면 대규모 분산 컴퓨팅 환경에서 대량의 데이터를 병렬로 분석이 가능하다.
- 흩어져 있는 데이터를 수직화 --> 흩어져있는 연관성 있는 데이터를 분류 --> filter를 거쳐 원하는 데이터를 추출(reduce)하는 분산처리 기술과 관련된 framework이다.
MapReduce의 원리와 처리 과정
Map의 처리 과정은 Map Task 단계와 Redece Task 단계로 이루어진다.
혹시 map과 reduce의 작동 원리에 대해 알고 싶다면..! 지난 포스팅에 간략하게 정리를 해 놓았으므로, 참고하자! [20210803] - [JS/Node] 고차함수
[20210803] - [JS/Node] 고차함수
이번 포스팅은 JavaScript 고차함수 (Higher order function) 에 대해 학습해보겠다. 1.고차함수 이해하기 Achievement Goals 일급 객체(first-class citizen)의 세 가지 특징을 설명할 수 있다. 고차함수(higher-..
sora9z.tistory.com
MAP
흩어져 있는 데이터를 연관성 있는 데이터들로 분류하는 작업
Reduce
Map에서 출력된 데이터에서 중복 데이터를 제거하고 원하는 데이터를 추출하는 작업
MapReduce 처리과정
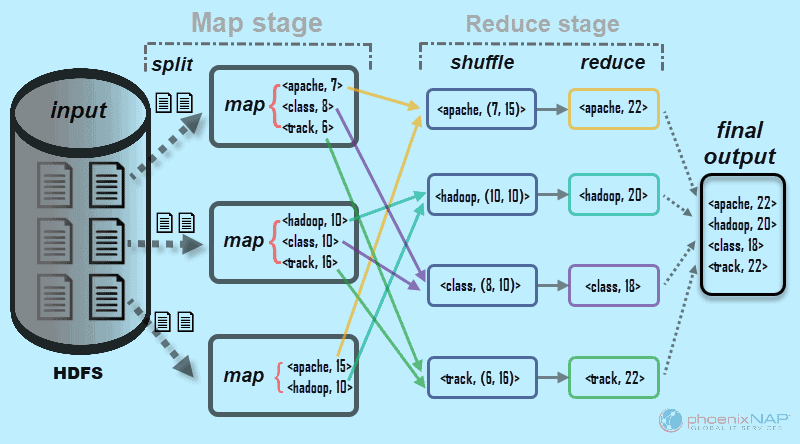
MapReduce 처리 과정은 위의 사진과 같이 이루어진다.
- Input : 데이터를 입력하는 과정
- Splitting : 데이터를 쪼개어 HDFY에 저장하는 과정
- Shuffling : Map task와 Reduce Task의 중간 단계로, Map 함수의 결과를 취합하기 위해 reduce 함수로 데이터를 전달하는 과정이다.
Reducin에서 모든 값을 합쳐서 원하는 값을 추출할 수 있다.
구글링을 하면서 보니 다양한 그림으로 설명을 참 잘해놓았다.

재미있게도 샌드위치를 싸는 과정을 이용하여 설명하는 글도 종종 있었다.

마지막으로, Map-Reduce의 장점과 단점
장점
- 단순하고 사용이 편리하다
- 유현하다.
- 저장구조와 독립적이다. 특정 질의 언어, 스키마의 정의 등에 의존적이지 않다는 점에서 비정형 데이터 모델을 유연하게 지원이 가능하다고 한다.
(정처기 공부를 안 했다면 무슨 말인지 몰랐을 것 같다) - 확장성이 높다
단점
- 복잡한 연산이 어렵다.
- 기존 DBMS가 제공하는 스키마, 질의 언어, 인덱스 등의 기능을 지원하지 않는다.
- 상대적으로 성능이 낮다. Map 과정이 진행될 때까지 Reduce는 시작할 수 없다.
'Computer Science' 카테고리의 다른 글
| [Computer Science][Codestates] - HTTP/Network 기초 - 1 : Client -Server Architecture , HTTP, IP, Port (0) | 2021.10.24 |
|---|---|
| [Computer Science][제로베이스 ]-운영체제 - System call & kernel (0) | 2021.10.24 |
| [Computer Science][CS50] 컴퓨터와 컴퓨팅 - TOPIC2 (0) | 2021.08.30 |
| [Computer Science][CS50] 컴퓨터와 컴퓨팅 - TOPIC1 (0) | 2021.08.30 |
| [Computer Science] 선언형 프로그래밍 VS 절차형 프로그래밍 (2) | 2021.08.05 |



